Introduction: Why Modern Data Warehouses Need a Smarter Foundation
As data sources multiply — from CRMs and marketing platforms to ERP and e-commerce systems — maintaining a unified, trustworthy view becomes increasingly difficult.
Traditional data warehouses often fail to keep pace with rapid schema changes, audit requirements, and evolving analytics needs.
To overcome these challenges, organizations are adopting Data Vault 2.0 architecture — a modern data modelling approach that enables flexible data integration, full auditability, and scalable analytics.
What is Data Vault 2.0?
Data Vault 2.0 is a data warehouse architecture and methodology developed by Dan Linstedt.
It’s built for agility, scalability, and transparency — integrating raw data from multiple systems while preserving its complete historical context.
Unlike rigid traditional models, Data Vault 2.0 separates raw data capture from business logic, enabling teams to adapt and evolve quickly as data landscapes grow.
Core Advantages
- Seamless integration across multiple systems
- Complete audit trails and historical tracking
- Scalable and automation-friendly ELT design
- Clear separation between technical and business logic
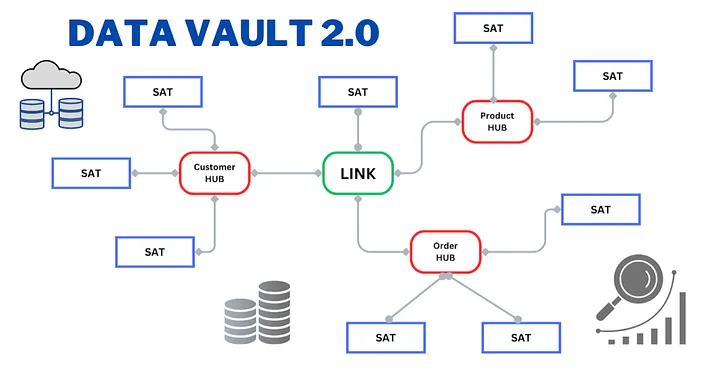
Core Components of Data Vault Architecture
Data Vault architecture is built around three key components:
1. Hubs — Business Keys
The single source of truth for core entities like Customer, Order, or Product.
Each Hub stores unique business keys and load metadata to ensure consistent identification across systems.
2. Links — Relationships
Links represent associations between business keys (for example, Customer places an Order).
They make relationships explicit and allow flexible joins without schema rewrites.
3. Satellites — Descriptive Attributes & History
Satellites contain the changing attributes and historical context of Hubs and Links.
Each record includes timestamps, source information, and versioning — preserving a complete audit trail.
The Data Vault 2.0 Architecture Layers
The full architecture extends beyond the core model, organizing your data flow from ingestion to analytics:
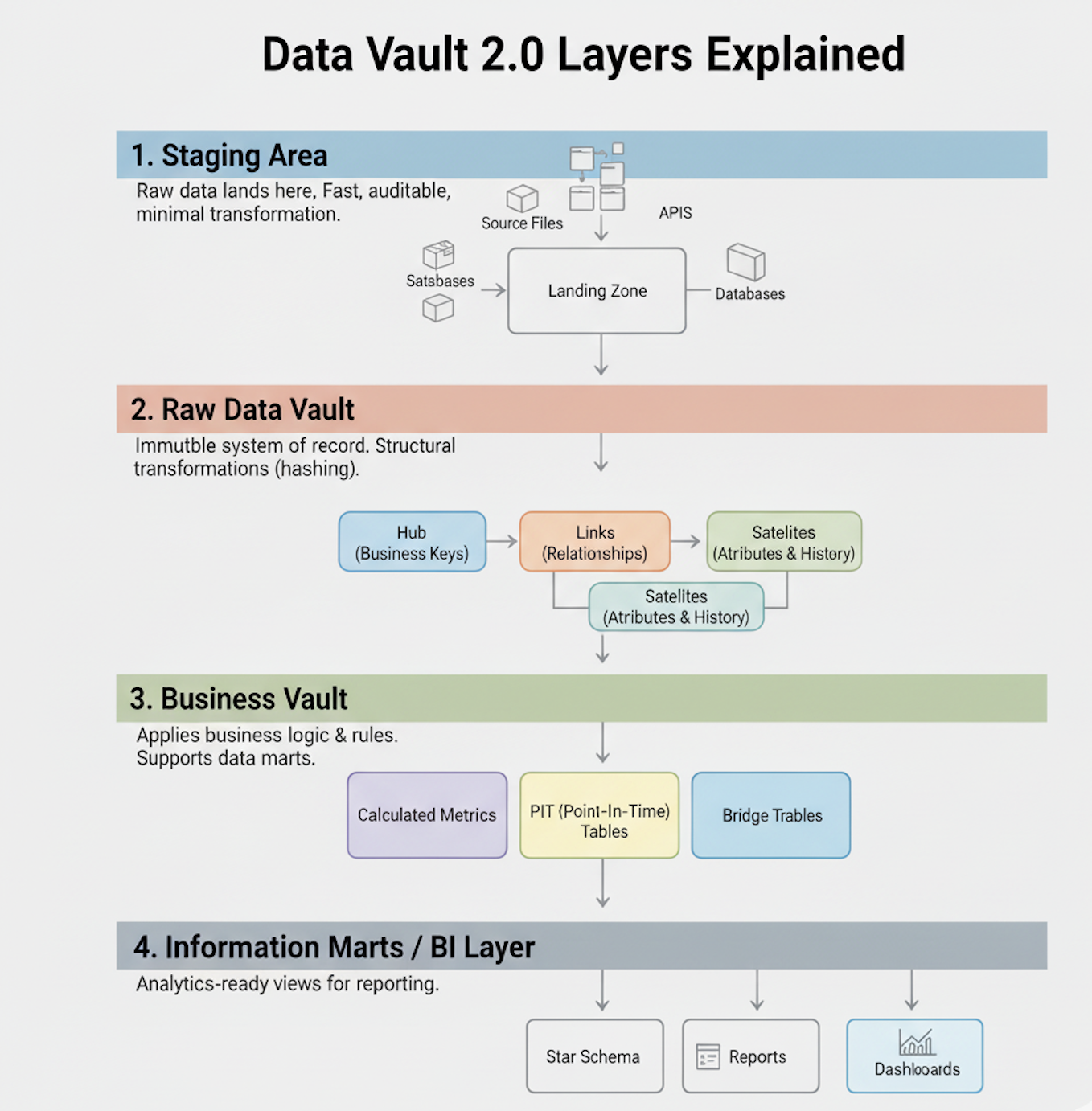
1. Source Systems
Your raw data from different channels lands here — CRM, ERP, marketing, or sales platforms.
2. Raw Data Vault
Preserves source integrity with Hubs, Links, and Satellites.
No business transformations occur here — only structure and lineage.
This layer forms the immutable system of record.
3. Business Vault
Applies business rules, calculations, and Point-In-Time (PIT) or Bridge tables for optimized querying.
It converts raw facts into business-aligned information while maintaining traceability.
4. Information Marts
Serves the analytics layer — reports, dashboards, and star schemas.
Because upstream layers retain full history, marts can be rebuilt anytime with confidence.
Why Organizations Choose Data Vault 2.0
| Challenge | How Data Vault 2.0 Solves It |
| Multiple inconsistent sources | Separate source Satellites, unified by business keys |
| Regulatory audit requirements | Immutable history with full lineage and timestamps |
| Frequent schema or business rule changes | Add Satellites/Links without refactoring |
| Fragile ETL pipelines | Template-driven, metadata-based ELT design |
| Slow reporting performance | PIT and Bridge tables improve analytical joins |
Top 5 Benefits
- Agility — onboard new data sources faster
- Scalability — parallelized data loading
- Resilience — rebuildable, versioned historical data
- Auditability — traceable from source to dashboard
- Clarity — clear split between raw data and business logic
Data Vault 1.0 vs Data Vault 2.0
| Feature | Data Vault 1.0 | Data Vault 2.0 |
| Data Load Method | ETL | ELT / Cloud-Native |
| Focus | Modelling only | Full Methodology (People, Process, Tech) |
| Automation | Manual | Metadata-driven automation |
| Performance Enhancements | Limited | PIT & Bridge tables |
| Scalability | On-prem systems | Cloud & distributed platforms |
Data Vault 2.0 is not just a schema — it’s an engineering approach to building maintainable, governed, and high-performance data warehouses.
When to Use Data Vault 2.0
Ideal for:
- Enterprises with multiple, evolving data sources
- Regulated industries needing audit trails
- Teams modernizing legacy ETL into cloud-native ELT
- Data platforms built on Snowflake, BigQuery, or Redshift
Avoid for:
- Small datasets with simple reporting needs
- Quick one-off analytical prototypes
Implementation Best Practices
- Use hash-based keys for consistency and scalability
- Automate Hub, Link, and Satellite load patterns
- Store metadata with every record — source, load timestamp, batch ID
- Group attributes logically into separate Satellites
- Build PIT/Bridge tables early for performant queries
- Keep business rules in Business Vault, not in Raw Vault
Example: A Simple Vault in Action
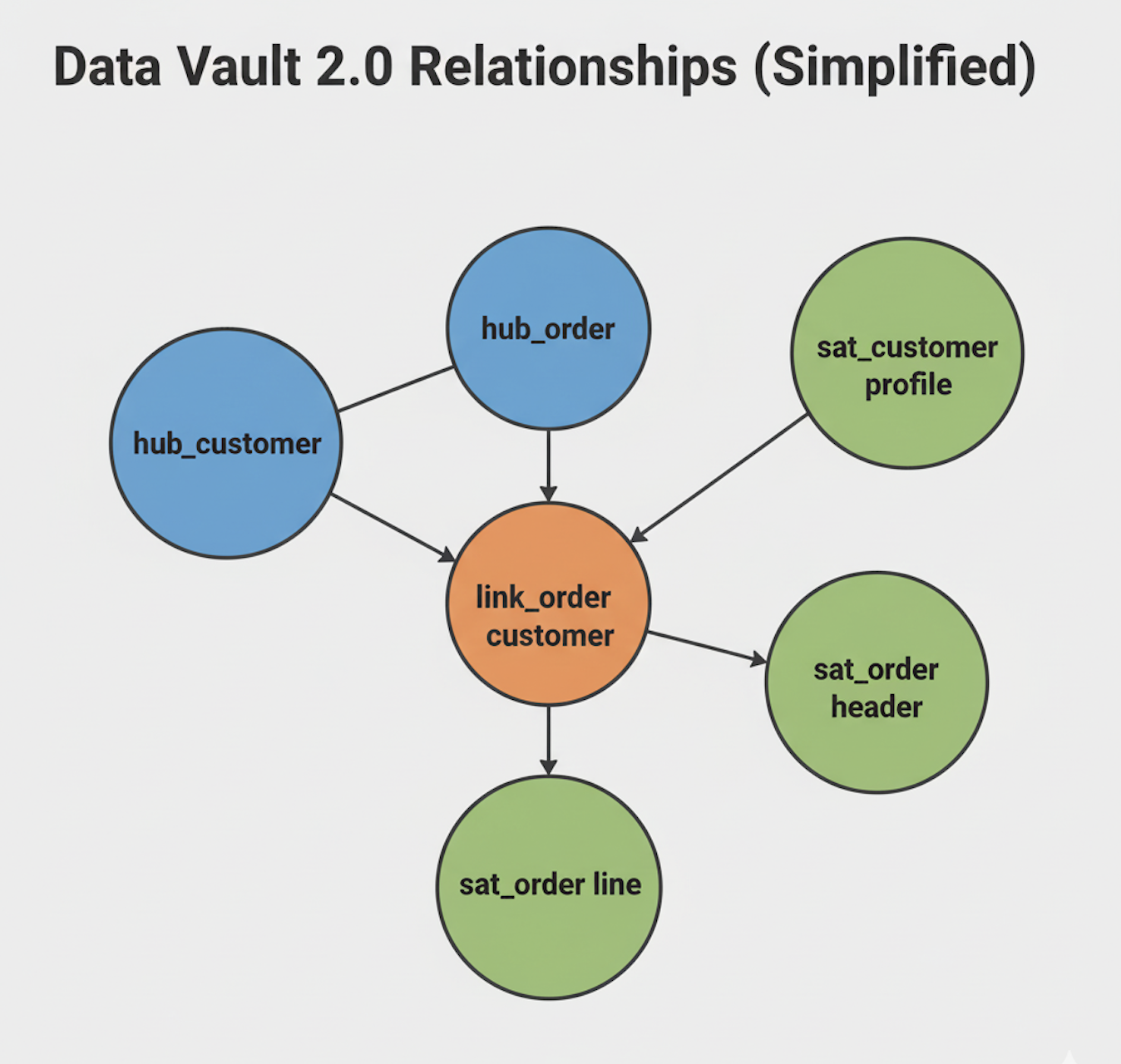
| Layer | Table Example | Purpose |
| Hub | Hub_Customer | Stores CustomerID, metadata |
| Satellite | Sat_Customer_Profile | Tracks address/email changes over time |
| Link | Link_Order_Customer | Connects Orders to Customers |
| Satellite | Sat_Order_Status | Maintains order state history |
Each update generates a new record — preserving every version for full historical accuracy.
Conclusion: A Scalable Future for Data-Driven Enterprises
Data Vault 2.0 provides a resilient data architecture that evolves as your business grows.
It ensures data integrity, lineage, and agility, while supporting advanced analytics and compliance.
For organizations looking to modernize their data foundation, Data Vault 2.0 isn’t just a model — it’s a blueprint for sustainable, future-ready data engineering.
🚀 Ready to Modernize Your Data Warehouse?
At DataOptix, we help enterprises design, automate, and scale their Data Vault 2.0 architectures — from raw data ingestion to actionable business intelligence.”Discuss in detail” with DataOptix team!”